
Cyber systems need intelligent defenses, and they are currently lacking. We have rote rules that specify how to protect our systems, but these rules can only protect against known attacks. We have methods for looking for unusual events, but these methods lack context and flag too many innocuous events as threatening. We even have machine learning approaches to classify bad events, but a human must still determine and specify each classification problem.
What we need is an autonomous protective controller with a global view and a causal understanding of the entire system. The controller could use its causal understanding to anticipate novel attacks by simulating adversaries; it could find attacks missed by signatures and understand the context behind anomalous events. Since it would be impractical to specify such an encompassing causal understanding by hand, we want it to be learned by the controller. If the controller could learn through active exploration, it could go beyond observation and be actively engaged in the system in an analogous way to how controlled experiments enable scientific understanding.
Previously, I argued that building an intelligent protective controller is a significant research challenge because cyber environments are constantly flooded with information. To overcome this obstacle, we are adapting research from developmental robotics to the cyber domain. The field of developmental robotics seeks to create algorithms that enable a robot to learn about the world in the same way a human child does. Children are able to learn in the presence of significant flows of information, and our approach is to extend a developmental learning algorithm called the Qualitative Learner of Action and Perception (QLAP) to the cyber domain. QLAP is a self-directed learning algorithm that autonomously learns high-level states and actions from low-level sensory input and motor output. Our extension of QLAP to cyber protection is called Cy-QLAP.
Cy-QLAP uses the QLAP algorithm to actively explore and learn about the environment. Once Cy-QLAP understands the environment, a human subject matter expert specifies a set of adverse events from which the controller should protect the system. Cy-QLAP then constantly monitors to see if it would be possible for an adversary to formulate a plan to bring about an adverse event. If it finds such a plan, Cy-QLAP can use its learned causal model of the system dynamics to thwart the possible attack before it happens.
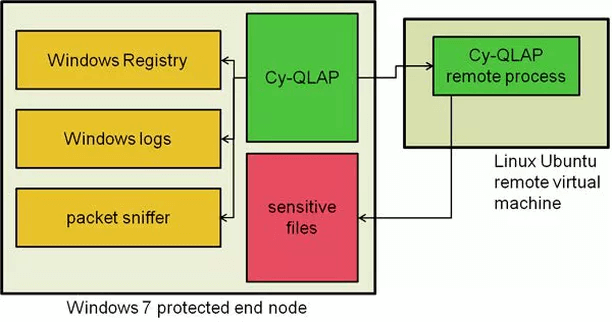
As a proof-of-concept experiment, we set up Cy-QLAP running on a Windows 7 machine. Cy-QLAP could examine the Windows registry, log files, and communication packets. Cy-QLAP could also trigger attacks through a remote Cy-QLAP process so that it could gain experience with a simulated adversary. Through autonomous exploration, Cy-QLAP learned how to defend the system from a method of file exfiltration. Specifically, Cy-QLAP learned that if a file share on a sensitive file was open, that file could be exfiltrated. It also learned how to close file shares, and Cy-QLAP would take the protective action of closing a file share on a sensitive file as soon as it was opened. The noteworthy result of this experiment is that Cy-QLAP learned how to protect the system without being told explicitly how to do so.
ABOUT JONATHAN
