
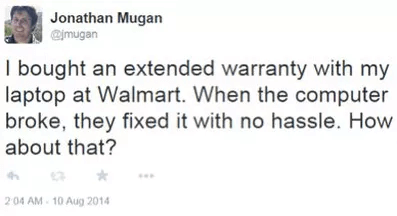
In a previous post I discussed the goal of understanding our world through the mirror world of social media. Social media is a reflection of our culture because many discussions that used to happen face to face or via the telephone now occur on sites like Twitter and Facebook. These digitized conversations can be read by computers, but can computers really understand what they are reading? The answer is, sort of. Computers understand human language like we understand a foreign language or a conversation going on in the next room. You can imagine a friend listening to such a conversation and reporting back, “I don’t know exactly what they were talking about, but it was something about Walmart and an extended warranty.” Computers comprehend language at about this level, and this post will explain how this is done and why it is useful.
To focus the discussion, we will use this tweet as an example.
UNDERSTANDING LANGUAGE THROUGH FRAMES AND ROLES
Computers can begin to understand our language using frames. A frame represents a concept and its associated roles. A classic example of a frame is a children’s birthday party. Birthday parties follow a script where there is a transfer of wealth (in the form of presents) from the parents of the attendees to the birthday girl or boy. The birthday party frame has roles for its different parts, such as venue, entertainment, and sugar source. One week, you might take your child to a party at a home where there is a clown and cupcakes. The next week, you may find yourself at Chuck E. Cheese surrounded by video games and cake. A computer can understand a lot just by recognizing the frame and mapping parts of the sentence to roles.
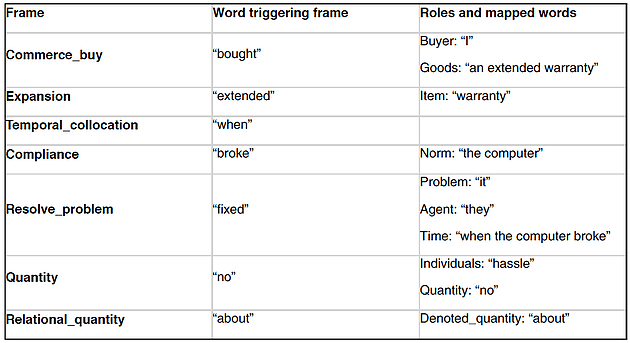
Seven frames is more than we would expect. Our brains are so efficient and well trained that we don’t have to consciously think about most of what we read. Frames such as Temporal_collocation and Quantity are not central to the point, but by looking at Commerce_buy and Resolve_problem, a computer can “understand” that something was bought and that a problem was resolved. We see a screenshot of the FrameNet Commerce_buy frame below.

ADDING TO UNDERSTANDING WITH NAMED ENTITIES
Computer understanding can be augmented by named entity recognition. Instead of looking for larger pieces of meaning represented by frames, named entity recognition seeks to identify known entities in our culture, like George Washington. Named entity recognition begins with an external data source that lists all known things, such as a machine readable version of Wikipedia. A computer program then reads our tweets looking for instances of those known entities. In the tweet we’ve been analyzing, a computer program [2] identified Walmart as a company in the tweet.
By applying both frame recognition and named entity recognition, the computer did not completely understand our tweet, but the computer did determine that there was a problem with something purchased at Walmart and that it was resolved. Although computers achieve only a shallow understanding when they read, they can read a lot, and this allows them to recognize trends. For instance, a computer could read Twitter and measure the number of resolved problems per company to get a sense of which companies were providing excellent customer service. Or a particular company, such as Walmart, could try a new warranty service and automatically know if it worked better or worse than the previous one.
OVERCOMING AMBIGUITY WITH MACHINE LEARNING
Both frame recognition and named entity recognition require more than looking for key words in text because the meaning of words is often determined by their context. We all know that time flies like an arrow, and fruit flies like a banana. Computers overcome ambiguity by learning from statistics on the surrounding text. Machine learning in this form augments the power of computer understanding.
Recall that the Commerce_buy frame was identified even though the word “buy” did not appear in the tweet. This is achieved partially by stemming words (mapping “bought” to the root “buy”) and partially by manually entering in other trigger words such as “purchase”, but this process is augmented by learning patterns from labeled data. Machine learning is also needed for named entity recognition. Consider a tweet that mentions “Washington.” Computers use context to determine if the intended meaning is the person, the state, or the capital. If the word “Seattle” appears in the tweet, the word “Washington” likely refers to the state.
WHAT KIND OF UNDERSTANDING IS THIS?
By combining machine learning with frame recognition and named entity recognition, computers can map the squishy natural language of humans to a concrete canonical representation. Of course, computers can only capture a fraction of the meaning, but even if they could capture all of it, would computers understand our language the way that we do? No. The concepts expressed in FrameNet are too high level. The roles expressed in Commerce_buy are Buyer and Goods. How is a computer supposed to understand those words? The good news is that there are other machine-readable sources of meaning called ConceptNet (http://conceptnet5.media.mit.edu/) and WordNet (http://wordnet.princeton.edu/) that attempt to define these terms and meaningfully link them to other terms. I dream about the day when we unify these frameworks in a computer understanding system.
If these systems were unified, computers still might not understand human language the way that we do because they would just have a network of symbols. By contrast, we understand the meaning of terms through physical interaction. We know what “heavy” means not by mapping it to other symbols but by mapping it to a set of remembered experiences encoded when it took physical effort to move objects. It’s an open question whether computers need physical experience to understand language fully.
Beyond the potential problem of needing physical experience for full understanding, the symbolic representations presented here may be too brittle to capture the subtleties of human language. For my next post on this topic, I will talk about computer understanding of human language using a relatively new computational method called Deep Learning. Deep Learning represents concepts using vectors instead of atomic symbols. These vectors represent multiple meanings at once and can combine in useful ways to enable reasoning by analogy. Deep Learning is quickly expanding the capabilities of computers, so stay tuned. Time flies like an arrow.
ABOUT JONATHAN

Jonathan is a Principal Scientist at DeUMBRA, where he investigates how machine learning and artificial intelligence can be used to make computers intelligent through access to context and knowledge. He earned a B.A. in Psychology and an MBA from Texas A&M University, and he earned his Ph.D. in Computer Science from the University of Texas at Austin. Jonathan is also the author of a book for parents and teachers called The Curiosity Cycle: Preparing Your Child for the Ongoing Technological Explosion.