
Editor’s Note: This is the second of two blogs by Jonathan Mugan explaining how, and the degree to which, computers understand our language in programs including social media platforms.
Before deep learning, the meaning embedded in the words we write was communicated to computers using human-engineered symbols and structures. My last blog post ( covered in detail how that can be done, and here I first review the symbolic methods WordNet, ConceptNet, and FrameNet as a contrast from which to understand the capabilities of deep learning. I then discuss how deep learning represents meaning using vectors and how vectors allow for more flexible representations. I then discuss how meaning encoded in vectors can be used to translate languages and even generate captions for images and answer questions about text. I conclude with a discussion of what deep learning still needs to truly understand human language.
WordNet from Princeton University is probably the most famous corpus of symbolic meaning. It groups words together when they have the same meaning and represents hierarchical links between groups. For example, it says that a car is the same thing as an automobile and that both are types of vehicles. ConceptNet (http://conceptnet5.media.mit.edu) is a semantic network that comes from MIT. It represents broader relationships than does WordNet. For example, ConceptNet says that bread is typically found near a toaster. However, there are too many interesting relationships to write down. Ideally, we’d like to represent that toasters are things into which one should not insert a fork.
FrameNet is a project from Berkeley University that attempts to catalog meaning using frames. Frames represent concepts and their associated roles. As we saw in my last blog post, a child’s birthday party frame has roles for its different parts, such as venue, entertainment, and sugar source. Another frame is that of a “buying” event where there is a seller, a buyer, and a good being sold. Computers can “understand” text by searching for keywords that trigger frames. These frames have to be manually created by humans, and their trigger words need to be manually associated. We can represent a lot of knowledge this way, but it is hard to explicitly write everything down. There is just too much, and writing it down makes it too brittle. Symbols can also be used to create language models that compute the probability of the next word in a sentence. For example, the probability that the next word is “tacos” given that I have written “I ate” is the number of times a corpus of text has “I ate tacos” divided by the number of times the corpus has the text “I ate.” Such models can be useful, but we all know that tacos are pretty similar to chimichangas, at least compared to toasters, but this model doesn’t take advantage of that similarity. There are lots of words, to store all of the triples you need storage the size of (num words×num words×num words), and this illustrates the problem with using symbols, there’s just too many of them and too many combinations. There needs to be a better way.
Representing meaning using vectors
Deep learning represents meaning using vectors, so that instead of representing a concept using a monolithic symbol, a concept is represented as a large vector of feature values. Each index of the vector represents some learned feature of the neural network, and vectors are usually around length 300. This is a more efficient way of representing concepts because the concept now is composed of features [Bengio and LeCun, 2007] [9]. Whereas two symbols can only be the same or not the same, two vectors have a degree of similarity. The vector for “taco” will be similar to the vector for “burrito”, and both vectors will be very different from the vector for “car.” Similar vectors can be grouped together like in WordNet.
Vectors even have internal structure so that if you take the vector for Italy and subtract the vector for Rome, you get a vector that is close to the vector you get when you subtract the vector for Paris from the vector for France [Mikolov et al., 2013]. We can write this as an equation as
Italy – Rome = France – Paris.
Another example is
King – Queen = Man – Woman.
We learn vectors with these properties by training neural networks to predict the words that surround each word [Mikolov et al., 2013] [10]. You can download already learned vectors from Google (https://code.google.com/p/word2vec/) or Stanford (http://nlp.stanford.edu/projects/glove/), or you can learn your own using the Gensim software library (https://radimrehurek.com/gensim/models/word2vec.html). It’s surprising that this works, and that the word vectors have such intuitive similarity and relationships, but it does work.
Composing meaning from word vectors
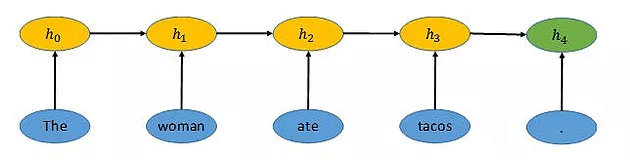
We have vectors that represent the meanings of individual words, how can we compose meaning from words and even write sentences? We use something called a recurrent neural network (RNN), shown below. The RNN encodes the sentence “The woman ate tacos.” into a vector represented by h . The word vector for the word “The” is taken to be h , and then the RNN combines h and the word vector for the word “woman” to get h1. The vector h then feeds along with the word vector for “ate” into h , and so on, all the way to h . The vector h then represents the entire sentence.
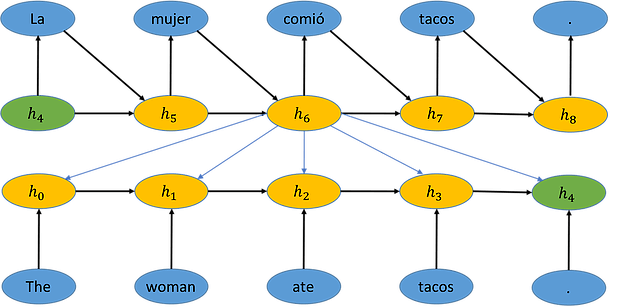
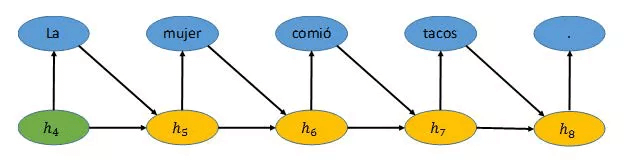
Once information is encoded into a vector, we can decode that information into something else [2], as shown below. For example, the RNN then translates (decodes) the sentence encoded into vector h into Spanish. It does this by taking the encoded vector h and generating the most likely word given that vector. That generated word “La” and h are then used to generate the new state vector h . Given vector h , the RNN then generates the most likely next word, “mujer.” This process continues until a period is generated and the network stops.
To do language translation using this encoder-decoder model, RNNs are trained on large corpuses of data where there are sentences translated between a source and a target language. These RNNs often have nodes that are quite complex [3], and the whole model can have millions of parameters that need to be learned.
We can make the output of the decoding any sequence, such as a parse tree [6], or even captions for images if you have enough examples of images with captions. To generate captions for images, you train a neural network on images to identify the objects in images. Then you take the weights from the top part of that neural network as a vector representation of the image and feed that into the decoder to generate the description [4, 7]. (For some great examples see here (http://cs.stanford.edu/people/karpathy/deepimagesent/) and here (http://googleresearch.blogspot.com/2014/11/a-picture-is-worth-thousand-coherent.html)).
From compositional meaning to attention, memory, and question answering
It’s tempting to think of the encoder-decoder method as a parlor trick, but we are slowly making our way toward real intelligence. We can think about decoding as answering a question, “What is the translation of this phrase?” Or, given the sentence to translate, and the words already written, “What should be the next word?”
To answer questions, the algorithm needs to remember facts. In the examples we’ve seen previously, it only remembers the current vector state h and the last word written. But what if we wanted to give it access to everything it had learned and seen? In the machine translation example, this would mean being able to go back and look at vectors h , h , h , and h while it was deciding which word to write next. Bahdanau et al. [1] created an architecture that does just that. The network learns how to determine which previous memory is most relevant at each decision point. We can think of this as a focus of attention over memories.
What this means is that since we can encode concepts and sentences as vectors, and we can use large numbers of vectors as memories and search through to find the right answer to questions, deep learning can answer questions from text. One example is a method [8] that, at its simplest, multiplies embedded question vectors by embedded memory vectors and takes the best fit to be the best answer to the question. Another example is a method [5] that encodes the question and the facts through multiple layers, and at the final layer the question is put through a function that results in an answer. Both of these methods learn by training on simulated stories with questions and answers and then answer questions like the ones shown below from Weston [8].

The next frontier is grounded understanding
The methods just discussed learned how to answer questions by reading stories, but some important aspects of stories are so obvious that we don’t bother writing them down. Imagine a book on a table. How could a computer learn that if you move the table you also move the book? Likewise, how could a computer learn that it only rains outside? Or, as Marvin Minsky asks, how could a computer learn that you can pull a box with a string but not push it? Since these are the kinds of facts that we don’t write down, stories will be limited in the kind of knowledge they can convey to our algorithms. To acquire this knowledge, our robots may need to learn through physical experience or simulated physical experience.
Robots must take this physical experience and encode it in deep neural networks so that general meaning can build upon it. If a robot frequently sees a block fall off a table, it should create neural circuitry that is activated for this event. This circuitry should be associated with the word “fell” when mommy says, “Oh, the block fell.” Then, as an adult robot, when it reads the sentence, “The stock fell by 10 points,” it should understand what happened using this neural circuitry.
Robots also must tie generalized physical experience to abstract reasoning. Consider trying to understand the implications of the sentence, “He went to the junkyard.” WordNet only provides a grouping of words for “went.” ConceptNet ties “went” to the word “go” but never actually says what “go” means. FrameNet has a frame for self-motion, which is pretty close, but is still insufficient. Deep learning can encode the sentence as a vector and can answer a question such as “Where is he?” with “junkyard.” However, none of these methods conveys a sense of a person being in a different place, which means that he is not here or anywhere else. We need either an interface between natural language and logic, or we need to encode some kind of abstract logic in neural networks.
Back to the practical: resources for getting started with deep learning
There are a lot of ways to get started. There is a Stanford class on deep learning for NLP (http://cs224d.stanford.edu/syllabus.html). One can also take Professor Hinton’s Coursera Course and get it right from the horse’s mouth (https://www.coursera.org/course/neuralnets). Also, there is a clear and understandable online textbook in preparation on deep learning from Professor Bengio and friends (http://www.iro.umontreal.ca/~bengioy/dlbook/). To get started programming, if you are a Python person, you can use Theano (http://deeplearning.net/software/theano/), and if you are a Java person, you can use Deeplearning4j (http://deeplearning4j.org/).
Conclusion
The revolution in deep learning is enabled by the power of our computers and the increased digitization of our lives. Deep learning models are successful because they are so big, with models often having millions of parameters. Training these models requires a lot of training data, which comes from our digital lives, and a lot of computation, which comes from Moore’s law. To progress to creating real intelligence, we still have to go deeper. Deep learning algorithms must learn from physical experience, generalize this experience, and tie this generalized experience to abstract reasoning.
ABOUT JONATHAN

Jonathan is a Principal Scientist at DeUMBRA, where he investigates how machine learning and artificial intelligence can be used to make computers intelligent through access to context and knowledge. He earned a B.A. in Psychology and an MBA from Texas A&M University, and he earned his Ph.D. in Computer Science from the University of Texas at Austin. Jonathan is also the author of a book for parents and teachers called The Curiosity Cycle: Preparing Your Child for the Ongoing Technological Explosion.
References
[1] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014.
[2] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014.
[3] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
[4] Andrej Karpathy and Li Fei-Fei. Deep visual-semantic alignments for generating image descriptions. arXiv preprint arXiv:1412.2306, 2014.
[5] Baolin Peng, Zhengdong Lu, Hang Li, and Kam-Fai Wong. Towards neural network-based reasoning. arXiv preprint arXiv:1508.05508, 2015.
[6] Oriol Vinyals, Lukasz Kaiser, Terry Koo, Slav Petrov, Ilya Sutskever, and Geoffrey Hinton. Grammar as a foreign language. arXiv preprint arXiv:1412.7449, 2014.
[7] Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan. Show and tell: A neural image caption generator. arXiv preprint arXiv:1411.4555, 2014.
[8] Jason Weston, Sumit Chopra, and Antoine Bordes. Memory networks. arXiv preprint arXiv:1410.3916, 2014.
[9] Yoshua Bengio and Yann LeCun. Scaling learning algorithms towards AI. Large-scale kernel machines, 34(5), 2007.
[10] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.