

Traditional computer programs rely on logic that is cut and dried; they therefore can only process a subset of our fluid world. But with the introduction of Large Language Models (LLMs), computers can now make “good enough” decisions in ambiguous contexts, like humans can, by using judgment. Having judgment means that programs are no longer limited by what can be precisely specified in numbers and categorical rules. Judgment is what AI couldn’t make robust before LLMs. Programmers could write decision trees or train machine learning models to make particular judgments (such as credit worthiness), but these structures were never broad enough or dynamic enough for widespread and general use. These difficulties meant that AI and machine learning were used sparingly and that most programming was still done in the traditional way, by stringing together symbols in a grammar that required an inhuman level of precision. With LLMs, all of that changes.
Judgement Expands What Programs Can Do
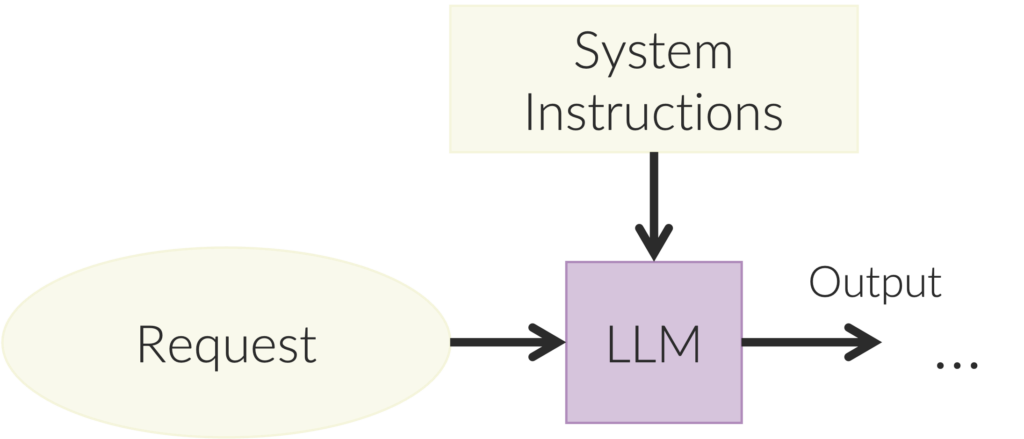
Most know LLMs from tools like ChatGPT, but in programming their deepest value lies in enabling judgment. Judgment allows programmers to create a new kind of flexible function to achieve tasks that can’t be precisely and exhaustively specified. A depiction of a judgment-enabled function is shown in the figure below. The request is the input to the function. The system instructions are what you want it to do, and the output is the function output. The request and the system instructions are concatenated together into the prompt sent to the LLM.
For example, if the purpose of the function was to determine which account an expense should be billed to, the system instructions would consist of descriptions of the different kinds of accounts and what expenses typically go to each, and the request would be a description of a particular expense. The system instructions are consistent across calls, but the request is different for each function call. The output of the function can be just like a traditional function’s output, such as a number, natural language text as a string, or a structured document in JSON.
Judgment Enables Flexible Workflows
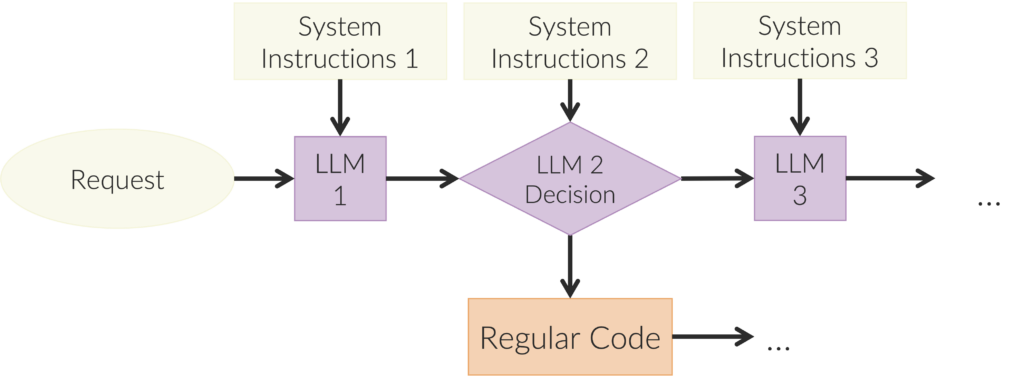
These judgment-enabled functions can be linked together into AI workflows, such as the one shown below. The LLMs can be used as nodes but also to make decisions about flows, and the LLMs can each be specially trained or can be the same LLM model but with different prompts. For example, a workflow was implemented with Microsoft Copilot Studio to help the consulting firm McKinsey route inbound emails to the McKinsey person best able to handle them. The system read the inbound email and looked at relevant external information and then sent the email on to the best person.
These types of workflow are often called “agents,” but as Woody from Toy Story might say, “That’s not agents; that’s functions with judgment.” We will see later what a proper agent looks like. For now, we can think of this workflow as a graph. (Note that LangGraph provides a good set of abstractions for building these workflows if you are just getting started.)
System Instructions Guide Judgment
We see in the above figures that much of traditional programming is shifting to writing system instructions. Writing effective instructions requires having a mental model of how LLMs are trained. This mental model should consist of two parts: (1) LLMs interpolate what is on the internet, and (2) LLMs are trained to provide helpful and safe responses. For interpolation, LLMs draw on vast internet data to generate responses mimicking how people might reply online. So if you ask the LLM about planting fig trees in central Texas, it’s not going to think from first principles about climate and soil composition; it’s going to respond based on what people on the internet say. This limited reasoning means that if your LLM needs domain-specific knowledge that isn’t widely available on the internet you need to add examples to the instructions. LLMs are amazing at pattern matching and can process more detailed instructions than many humans have patience for, so you can be as precise and detailed as you want.
The second part of your mental model should be that LLMs are trained to provide helpful and safe responses, which means that the outputs won’t be exactly like someone on the internet would say. Instead of being like the fabled StackOverflow user who smugly suggests that you redo your work using karate-lambda calculus, LLMs are shaped to provide direct and polite answers. This second training also means that sometimes the LLM will refuse to answer if it thinks the request is dangerous. Different LLM providers offer different settings for this, but in general it helps to tell the LLM why it should respond, such as telling it what role it plays in society, “You are a medical assistant, please respond based on the following criteria …”
In my work, I’ve found that the judgments provided by LLMs are currently not as good as those of a conscientious human, but they are often better than a distracted one. More significantly, the kinds of mistakes that LLMs make are different than those a human would, so workflow designs need to take unusual failure modes into account. However, one way to improve the judgments of LLMs is by making sure that they have enough context to answer the question.
Dynamic Context Improves Judgment
LLMs make better judgments when they have sufficient context. For example, an LLM acting as a law assistant may need to be fed the details about the law related to the particular case in the request. These details serve as context for the request and can then be concatenated into the prompt along with the system instructions and the request. One common way to collect the right context for a request is called retrieval augmented generation (RAG). You’ve probably heard about RAG. When a request comes in, a process converts the request into a vector and then compares that vector against the vectors of chunks of text in a database. The chunks of text with the most similar vectors to the request are then added to the context.
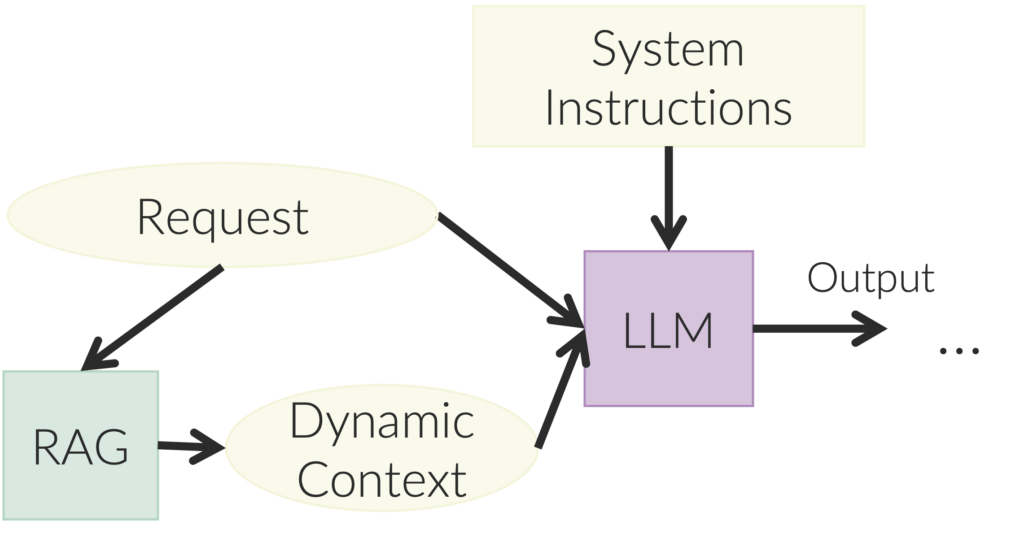
As LLMs begin to be used more in programs, your intellectual property will increasingly take the form of system instructions and contexts. We often hear about “prompt engineering,” but the term is misleading, suggesting clever tricks to manipulate LLMs rather than clear, precise instructions. People are now moving to a better term, context engineering. Beyond understanding how LLMs are trained, crafting effective prompts is about giving the LLM everything that it needs to know to make good judgments. The system instructions and context will often include documentation that was originally written for people to follow, and going forward, we will increasingly find ourselves writing documentation directly for LLMs. This documentation specifies how the system should work, and the system is then “rendered” into existence by the LLMs. In my work, I often find that if the LLM doesn’t do what I want it’s because I haven’t finished thinking yet. The process of rendering the design shows where it is lacking.
A context can be any kind of information, such as computer code, and LLMs are now reading our code and acting as assistants to programmers. As these assistants get better, they have incorporated more context. Recently, we have seen a progression of four levels of programming assistant:
- They started as a smart autocomplete that only looked at the current file.
- They then began offering suggestions for code fixes based on requests by looking at the current file and maybe a few others.
- They then progressed to actually changing the code based on requests (e.g., so called “agent mode” in Github Copilot).
- In their latest incarnation, they can look at the whole codebase as context and make general changes (such as with Claude Code and the new OpenAI Codex).
Funnily enough, extra-compiler semantics such as comments and good variable names used to be important for us humans but not for the computer running the code, but with LLM assistants we now have computers also reading the code, and those good practices do matter for these computers because they make the context more useful by enabling the LLM to map it to what it learned during training.
Judgment + Loop ≈ Agency
LLMs are surprisingly human-like in their limited ability to track complex world states and how those states will unfold. We humans are good at getting the gist, but for specifics, we need tools, such as databases. LLMs can access external tools such as calendars, calculators, and computers, just like humans do. A tool call can also be a web search, a function call of regular code, or a database lookup. As we see in the figure below, just like with RAG, these tools add to the context to help the LLM better respond to the request. The difference from RAG is that the LLM chooses which tool to call, and it continually calls tools in a loop until it decides that it has sufficient context to answer the request, a pattern sometimes called ReAct.
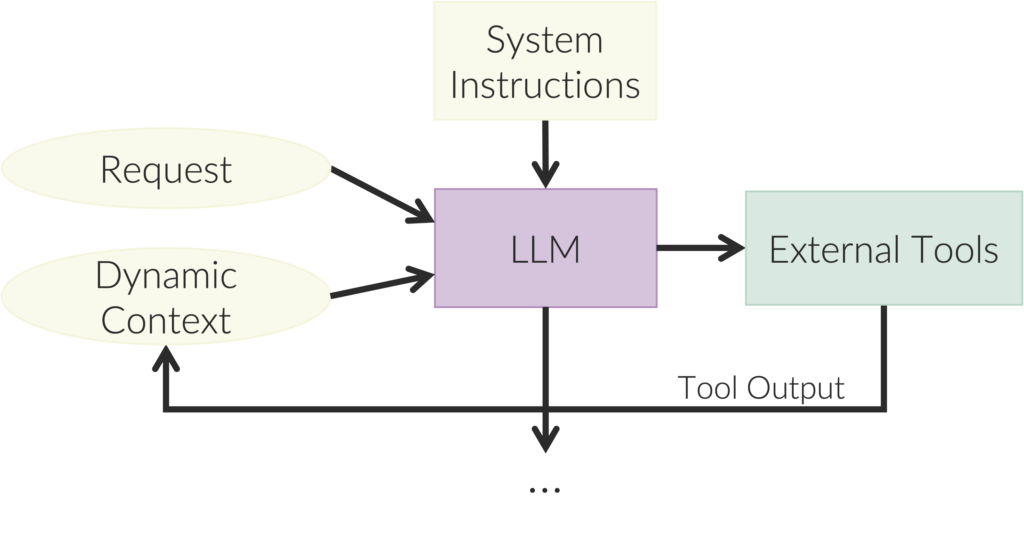
Tool calling in this way is like a robot sensing and acting in the world. Calling tools is where the system gets information. It can choose which tool to call, like a human choosing where to look as we enter a new room. Tools can also be considered “actions” if they change the external world, such as by adding a record to a database. The system makes tool choices in a loop and decides when it is done. Paraphrasing William James, Michael Levin states that “intelligence is the ability to reach the same goal by different means.” This combination of judgments and loops is agency. But who’s watching the agent?
Judging One’s Judgments ≈ Self-Awareness
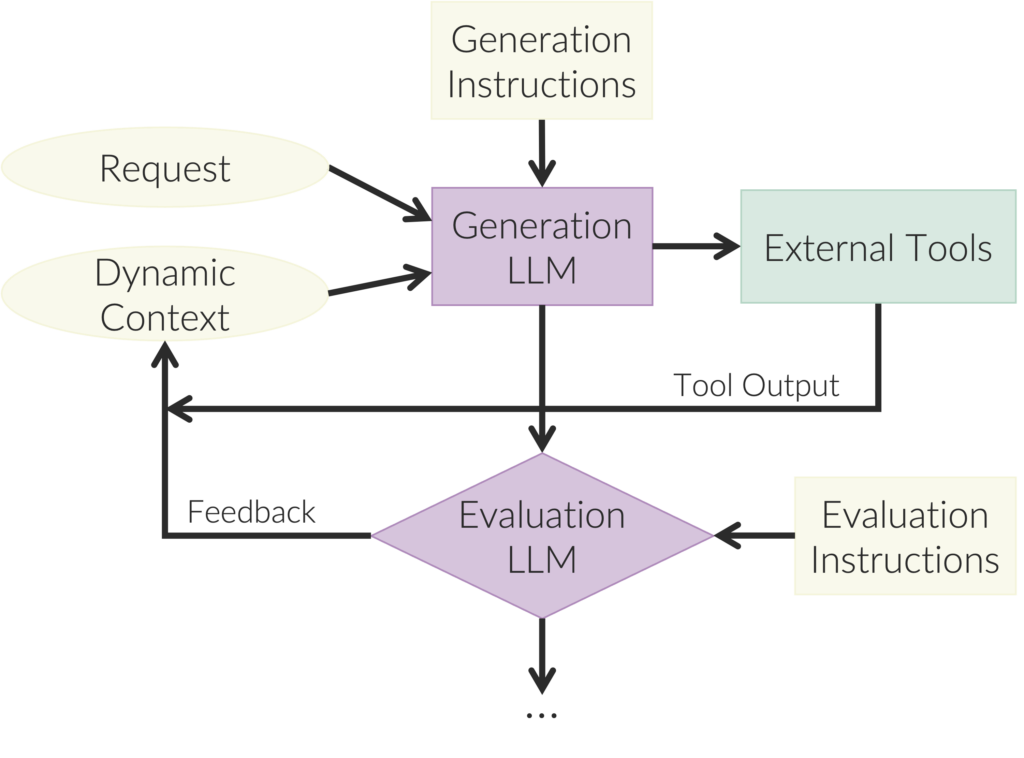
To achieve a form of self-awareness, we can combine a Generation LLM, which uses judgment to produce outputs, with an Evaluation LLM, which uses judgment to assess those outputs, as shown below. This second-level reflection is necessary for a recognition of a “self” that is separate from the outside world, and together, these two LLMs form a self-monitoring system in which the Evaluation LLM provides feedback to continually improve the Generation LLM.
These dual judgments enable an agent to search through a space of solutions to a problem. Search is an old approach in AI where the system is in some state, it evaluates a set of actions, and each action takes it to a new state. The system explores these states until it finds a state that is a good solution. Applying search is beset with two goblins. The first is that the space of possible states is often too big to exhaustively explore. Judgment attacks this by enabling the agent to smartly choose which action to try next. The second goblin is that you need some way of knowing whether you are making progress toward the solution and whether the current state is a good-enough solution to the problem. Fortunately, this goblin is also slayed by judgment. Search is closely related to another venerable AI method called generate and test, where the generate function creates candidates and the test function determines the value of those candidates, and both of those processes benefit from judgment.
For an example of search (or generate and test), imagine that the LLM system is designing a new drug. The Generation LLM needs to propose good candidates or changes to existing candidates, and the Evaluation LLM needs to estimate whether such a candidate might work. Once the Evaluation LLM determines that the candidate might be suitable, it can pass it to the next system for further testing.
Agency + Self-Generation ≈ Life
Programs run on hardware, but hardware is elemental, like oxygen. Computer systems are made of code.
LLMs can write code just as well as natural language, and the simplest way to do it is to pass the code to an external code interpreter tool, as is depicted two figures above. The tool executes the generated code in a sandbox and provides the output to the context. For example, if the user wants to know the number of days until the winter solstice, the LLM can generate a program that computes it and can pass that program to the program interpreter tool. The interpreter can then run the program and pass the output, the computed number of days, to the context. The LLM then reads this context and determines it has the answer and passes it to the user. Such transient code reveals a new truth. Programs have always been held as artifacts, understood and maintained, like contracts between us and our systems. But with LLMs now generating code on the fly, much of it assumes the nature of the spoken word more than of documents. It is formed, executed, then shed. The work flows onward.
Yet the generation deepens. A more sophisticated method sees the Generation LLM crafting the code and the Evaluation LLM determining how to improve that code. This Evaluation LLM can be paired with a verifiable evaluation when one is available, such as whether the code solves a math problem or how fast it can solve it. If multiple candidates are generated and mixed and improved, code generation can be akin to Darwinian evolution, such as with the recent methods of AlphaEvolve and Darwin Gödel Machines. This generated code can have any purpose, such as maximizing some mathematical function or creating a design for a spaceship. The judgment provided by the Evaluation LLM is particularly important when there is no concrete evaluation function and solutions must be judged based on fuzzy criteria.
Code generation can also be used to build new external tools available for the agent, so that the system can expand itself. One example is the Voyager system that builds tools made of code to help it play Minecraft. A system that can extend itself represents a significant advance for machine learning. Neural networks such as LLMs are trained with millions of examples, with each example modifying the model parameters ever-so slightly. This process is too slow. The future lies with autonomous systems that can write new modules in code that makes them smarter in leaps and bounds.
Autonomously writing new modules extends toward life itself. Biological life started because molecules came together that by chance formed systems capable of self-maintenance and self-replication. Life is different from a crystal or something like fire because it actively maintains itself by continually adapting to the environment in a loop. The bacterium E. coli exhibits goal-directed behavior in the sense that it continually adjusts its motion toward food gradients, while fire spreads passively. In addition to having agency, biological organisms can build their own parts, a process called autopoiesis. Computer systems that can write their own code are in a sense building themselves. They have no drive to continue to exist, but we do give them rewards for getting smarter, and as we learn to improve and better harness this judgment, the depth of understanding held by computer systems will become significant.
Life + Self-Awareness ≈ Consciousness
As more code becomes generated by AI, some computer systems may become incomprehensible, so that understanding them will be like disentangling the intricate workings of a biological cell. This transition from humans writing programs to computer systems reading and writing their own code marks a fundamental turning point. In the past, beyond the human author, there was only the CPU blindly executing instructions; there was no one besides the human capable of making judgments about that code to prevent things such as buffer overflows, SQL injections, and other forms of mindlessness. But adding LLMs capable of reading and writing their own code marks the transition of computer systems from passive automatons to active participants. This ability to read their internal programming means that computers can introspect multiple levels down into their own actions and motivations. For the first time, computers can run processes but not be entirely in those processes. They can use internal attention to focus on different aspects of themselves, generating a kind of strange loop that might someday lead to consciousness.
Thanks to Kyle Ferguson, Courtney Sprouse, and Truman Wilson for their helpful comments and suggestions.